Adapting Radix Trees
NLnet Labs continuously strives to push the performance of its products. Over the course of the past year we researched improvements to main-memory databases for our authorative nameserver, NSD.

By Jeroen Koekkoek
Motivation
NSD serves zone data from a main-memory database and uses the copy-on-write (COW) behavior of the fork system call to reduce code complexity, achieve lock-free concurrent access and increase robustness. Zone updates are published by forking and applying all (incremental) updates received thus far. While working on the code that handles zone updates, I figured applying updates one-by-one would reduce complexity considerably as there is quite a bit of plumbing in place to communicate updates to the main server. Every reload involves forking new servers and terminating the existing ones, which is relatively expensive and must therefore be throttled. Utilizing shared memory in combination with read-copy-update (RCU) came to mind and a new project was born.
Usage of an RCU mechanism implies there can only be one-way references. Hence, the red-black tree implementation that is currently used is not fit for this purpose. And, because the tree cannot be traveled upwards and worst-case depth is unknown with red-black trees, range scans can become terribly inefficient. Apart from the tree structure itself, each domain object also keeps references to additional domain objects to improve lookup performance. e.g. the closest encloser. These references also cannot exist if RCU is to be used. Of course, that’s not a problem if overall performance matches or exceeds current performance.
Radix trees offer fixed depth paths and fast lookups and thus meet both criteria, but are typically not very space efficient. Domain names consist of labels, which consist of octets. Most domain names will stick to the preferred name syntax (RFC 1035 section 2.3.1), but every octet can have any value between 0x00 and 0xff. Every node must therefore be able to hold 256 references to child nodes. Some tricks can be applied, but even the radix tree that is currently shipped with NSD requires about twice the amount of memory than the red-black tree to store the same data.
The Adaptive Radix Tree (ART)
The Adaptive Radix Tree (ART), as proposed by Leis et al. in 2013, is a trie structure for modern computer systems that offers great performance and space efficiency. Worst-case overhead is no more than 52 bytes per key, but this is often much lower in practice, while lookup performance is comparable to that of hash tables. The paper provides great detail and benchmarks various tree implementations, but a quick summary of the clever tricks ART applies is provided below.
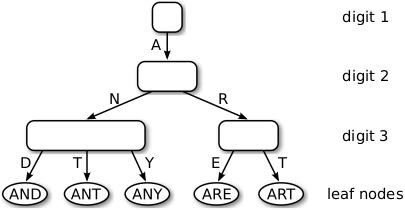
Adaptively sized nodes
Horizontal compression is applied by adapting the size of inner nodes. Nodes can have sizes of 4, 16, 48 and 256, each capable of holding the respective number of references to child nodes, and are grown/shrunk as needed. Fixed sizes are used to minimize the number of memory (de)allocations. Nodes of sizes up to 48, map keys onto edges using two separate vectors. Nodes of size 16 make use of 128-bit SIMD instructions (SSE2 and NEON) to map a key onto an edge to improve performance.
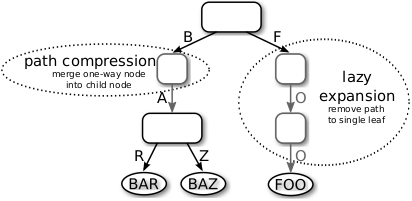
Path compression
Inner nodes that have only one child are merged with their parent and each node reserves a fixed number of bytes to store the prefix. If more space is required, lookups simply skip the remaining number of bytes and compare the search key to the key of the leaf once it arrives there. The fixed size is usually enough in practice and avoids memory fragmentation.
Lazy expansion
Inner nodes are created only to distinguish at least two leaf nodes. Paths are truncated. Pointer tagging is used to tell inner nodes apart from leaf nodes.
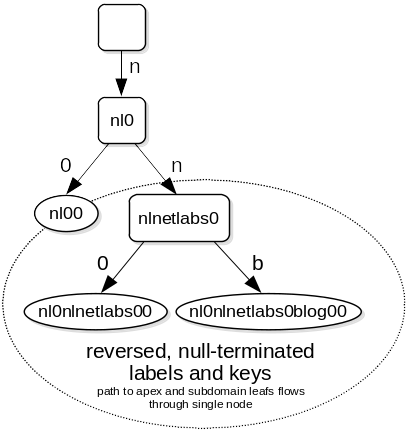
The Nametree
The numbers presented in the paper were promising enough to investigate if the tree structure can be used to efficiently serve domain name data. This section documents the domain-specific (pun intended) changes I made to significantly speed up lookups over the existing radix tree while using less memory than the red-black tree.
Key transformation
Domain names cannot be used as keys without modification. The order of labels must be reversed to allow for range scans, e.g. for zone transfers. Adaptive radix trees also cannot store prefixes of other keys. The paper suggests keys be terminated with a value that does not occur in the set. However, octets can have any value between 0x00 and 0xff, which would imply a multi-byte encoding scheme is required. Luckily, comparisons between uppercase and lowercase letters must be done in a case-insensitive manner (RFC 1035 section 2.3.3). By transforming uppercase letters to lowercase, 26 values are freed and the range can even be compressed to lower worst-case space consumption for nodes of size 48 and 256. 0x01 is added to every octet with a value less than 0x41 and 0x19 is subtracted from octets with values greater than 0x90 so 0x00 can be used to terminate labels and keys while preserving canonical name order (RFC 4034 section 6.1).
Denser inner nodes
Nodes have an unsigned 32-bit integer member to hold the prefix length by default. Domain names have a maximum length of 255 octets, an unsigned 8-bit integer is therefore sufficient and by reducing the size of the prefix vector from 10 to 9 bytes, 32-bits can be saved for each inner node.
Extra node types
Node sizes jump from 16 to 48, but as the tree will mainly store hostnames, adding extra types in between can save a lot of memory. Firstly, we introduce a node of size 32, which benefits from the 256-bit SIMD instructions (AVX2) found in Intel and AMD processors since around 2016. Secondly, we introduce a node of size 38 that stores hostname-only entries without extra overhead by using an alternate key scheme. Upon lookup or insertion, the key undergoes one more transformation to determine the index. Whether the node of size 38 is warranted remains to be seen, but the idea is interesting nonetheless.
Anonymous leaf nodes
Leaf nodes are recognized by a pointer tag and can be anonymized as long as the prefix can be retrieved to verify the key matches the search key (path compression and lazy expansion). By extending the lookup algorithm to use a pre-registered function to retrieve the key, domain objects themselves can be tagged and inserted directly in the tree. This measure saves an indirection and saves the memory otherwise required for the leaf node at the cost of needing to transform the key of the leaf node on lookup, but that problem is easily solved by passing the domain name on lookup too.
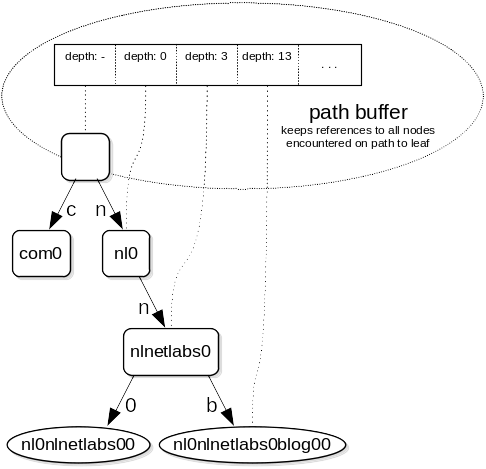
Path tracing
Domain names have a maximum length of 255 octets, the worst-case maximum height of a path is therefore 255 levels. This limitation can be used to record the entire path leading up to a leaf, which can be used to iterate a zone in canonical name order without keeping parent pointers in child nodes and allows fast resolving of enclosing nodes by traveling up the path. Each server process keeps a path buffer and recycles it per query to minimize memory allocations. The path can also be used for quick insertion of zone data as paths are fixed and thus can be reused.
Ordered nodes of size 48
Most node types store values in the order of the keys, except for nodes of size 48. By ensuring all nodes store values in order, given a path, the next or previous closest node can be looked up without comparing key values.
Measuring NSD tree performance
The nametree is implemented on a separate branch in the NSD repository. The branch adds an extra treeperf target to measure performance of each tree implementation. Three binaries (rbtreeperf, radtreeperf and nametreeperf) will be generated, each binary will read domain names from a text file and insert them into the database to determine both time spent to query and insert the name and the amount of memory used to store all data.
$ git clone https://github.com/NLnetLabs/nsd.git
$ cd nsd
$ git checkout nametree
$ autoconf && autoheader
$ ./configure
$ make treeperf
A small script is available to download the Umbrella Popularity List from Cisco and prepare for the benchmark.
$ tpkg/treeperf/top-1m.sh
To find out how each tree performs.
$ time ./rbtreeperf count top-1m.list
98942864 bytes allocated
real 0m1.679s
user 0m1.636s
sys 0m0.040s
$ time ./radtreeperf count top-1m.list
354408408 bytes allocated
real 0m1.429s
user 0m1.291s
sys 0m0.134s
$ time ./nametreeperf count top-1m.list
91049872 bytes allocated
real 0m0.792s
user 0m0.757s
sys 0m0.034s
The nametreeperf binary differs slightly from the other two. a) It allocates the domain name with the domain structure to demonstrate where extra space can be saved. Leaving that out would put memory usage slightly (~1%) over that of the red-black tree; and b) It reuses the path generated by the lookup for insertion as well to demonstrate path reuse.
What’s next?
The nametree has potential and the amount of memory can be further reduced by removing more references at the domain object level. Whether or not NSD will ever move to a shared memory model is uncertain, the current implementation is rather elegant and since zones must be updated atomically, there are a few more hurdles to overcome, but the tree may be used to significantly increase performance. Before it can be used to answer queries though, the lookup process involved with answering said queries will have to be altered to use the path buffer to its fullest. As it stands, the implementation has few dependencies on the rest of the code base and we wanted to share the ideas because they may prove useful to other projects. We’d love to hear if the implementation or the ideas presented are useful to your project. Of course, please share any bugs or improvements you find.