Leaping through RPKI history with Ziggy
RPKI, the Resource Public Key Infrastructure, is an important cornerstone in securing the BGP routing system on the Internet. In its…

By Roland van Rijswijk-Deij
RPKI, the Resource Public Key Infrastructure, is an important cornerstone in securing the BGP routing system on the Internet. In its current form, RPKI enables resource owners (e.g. holders of IP prefixes) to issue digitally signed statements about which autonomous systems may originate routes for those prefixes, using so-called Route Origin Authorisations (ROAs). These ROAs can then be validated independently and used by routers to check if BGP updates that they receive from peers are legitimate. By checking if BGP announcements are valid, routers can prevent prefix hijacks from propagating, protecting Internet traffic from honest misconfigurations, but also from malicious announcements.

Since 2018, NLnet Labs has a new line of open source projects focusing on RPKI. Our first project in this space is Routinator, which is so-called Relying Party (RP) software. It plays the important role of validating ROAs and outputting so-called Verified ROA Payloads (or “VRPs” for short) that routers can use to filter out invalid BGP updates. Of course, given the vital role it plays, we thoroughly test every release of Routinator carefully with current RPKI data before releasing it. But then we got our hands on some great data archived by our good friends at the RIPE NCC: all historic RPKI data going back to the very origins of the protocol in 2011. This was, of course, an opportunity we could not resist: we wanted to run all of that data through Routinator to test it, and to take a peek into RPKI history at the same time. This long-read blog tells the story of how we did this with a tool called “Ziggy” and what we found.

Al: “Ziggy says the odds are real good.”
Sam: “How good?”
Al: “Oh, you know. They’re way up there.”
To use Routinator on the archived RPKI data, we need a couple of things to come together. We need to grab data for the right date from the RIPE archive, we need to figure out which objects are in the archived data, we need to recreate the RPKI trust roots (so-called “TALs”) for that date and finally, we need to run Routinator as if it were that day. Being the sci-fi geeks that we are, we of course had to pick an appropriate name for the tool that would perform this task. Given that we were essentially making Routinator travel back in time, we decided to call the tool “Ziggy” after the eponymous computer in 1990s sci-fi classic “Quantum Leap”. And of course we open-sourced Ziggy so you can play around with the data too, more details on how to use Ziggy yourself can be found at the end of this post.
First things first: what could we validate?
The first thing we wanted to find out is what we could validate. So we used Ziggy to run all the data we got from RIPE through Routinator. This took over 15 hours, but considering that this was over 8 years of data (to be precise: 3109 days of data) that was pretty impressively fast!
Cool, so apparently we could validate something. What does this data look like? The first thing we did was plot the number of VRPs that came out of the validation, giving us the following two plots (IPv4 on the left, IPv6 on the right):
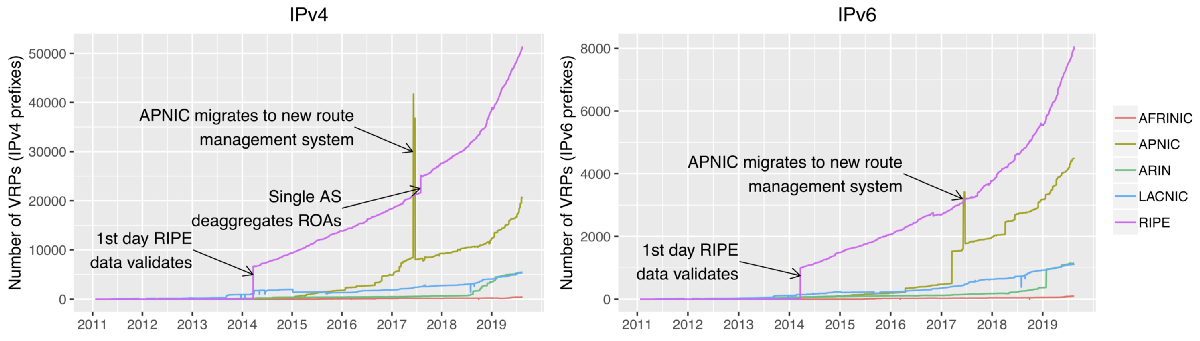
There are a couple of takeaways from these graphs. First: before early 2014, very little data could actually be validated (first arrow in the plot). The reason for this is simple: the data before then didn’t quite comply with the RPKI standards, and Routinator cannot validate it because of that. We are working on a way to process this data in any case, but note that a modern validator would have ignored the data, so in essence it is “RPKI unknown” and should not be used for filtering.
The second thing to note is a significant spike in both plots for APNIC around the middle of 2017. This is due to massive deaggregation of the ROAs for three autonomous systems. Effectively, these ASes had only few ROAs each for a large prefix with the MaxLength attribute set to /24 before the event, and during the event these ROAs were replaced by a very large number of ROAs each covering a single /24 from the larger prefix. We asked APNIC about this, and they commented that this was a mistake during the introduction of a new generic route management system that covers both IRR and RPKI. When internal monitoring noticed the mistake, they stopped the process, fixed the mistake and restarted the migration. There is another deaggregation event for a single AS in the IPv4 data (marked by an arrow); this appears to be a purposeful deaggregation of a large prefix into ROAs for single /24 prefixes. There has been some debate about whether MaxLength should be used if not all of the more specific prefixes allowed by the MaxLength setting are actually announced. We speculate (but cannot confirm) that this has led to at least some ASes deaggregating their ROAs.
Finally, and most importantly: the use of RPKI is growing rapidly, especially in the last two years. In fact, we have just passed 100,000 VRPs! 🎉
Zooming in: deployment of RPKI in real world practice
Now that we have a general overview that shows that RPKI use grew over time, let’s zoom in on some details that show how RPKI use has changed over time. In particular, we will zoom in on two things: the use of the MaxLength attribute and the average size of prefixes and MaxLength attributes in ROAs over time. We start with a big plot:
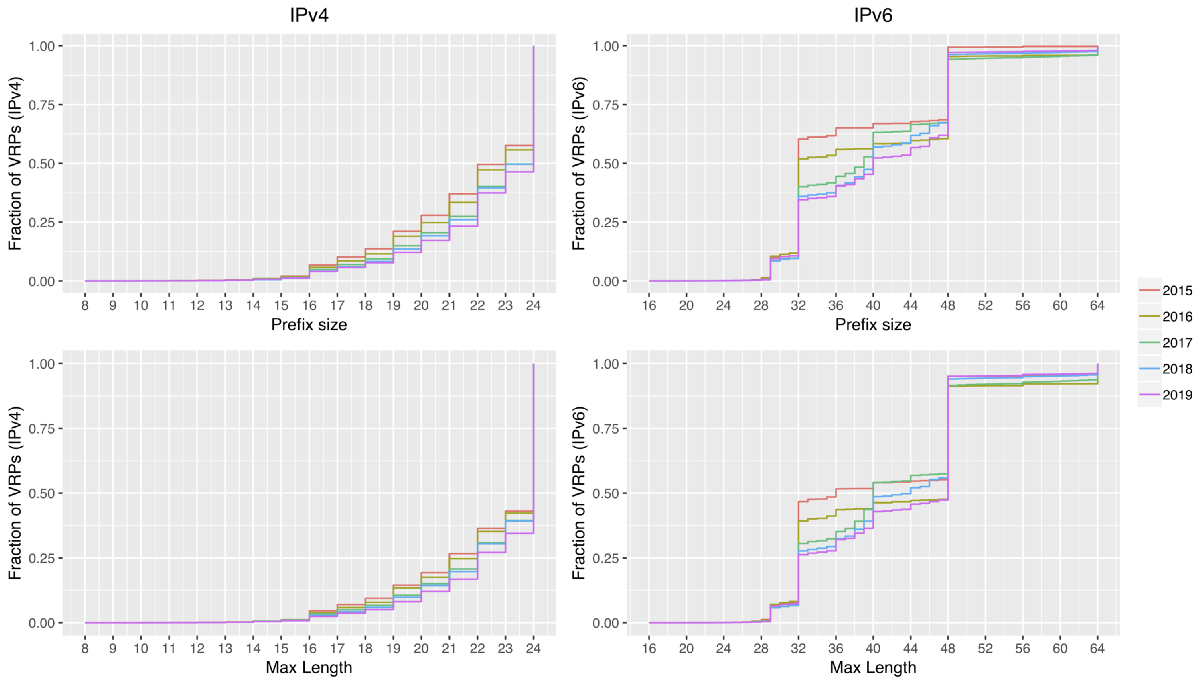
This plot shows a so-called Empirical Cumulative Distribution Function (ECDF) of the prefix size encountered in ROAs (top, left: IPv4, right: IPv6) and the MaxLength value encountered in ROAs (bottom, left: IPv4, right: IPv6). Each plot shows the distribution on August 1st in five different years (2015–2019). And what each plot clearly shows is a trend toward ever smaller prefix sizes, both in the prefix covered by the ROA and in the MaxLength set in the ROA. In 2015, 42.4% of ROAs for IPv4 had a prefix size of /24, in 2019 this had grown to 53.6% (well over half of ROAs). For MaxLength we see a similar development with 56.9% of ROAs having a MaxLength of /24 in 2015, growing to 65.6% in 2019. Given that the IPv4 address pool is severely exhausted, this is unsurprising. Routing data also reflects this trend.
Interestingly, the trend of decreasing prefix sizes in ROAs is also clearly evident in the IPv6 graphs. In 2015, a staggering 60.4% of IPv6 ROAs had a prefix size of /32 or bigger, in 2019 this had dramatically decreased, with almost half of IPv6 ROAs having a prefix size of /40 or smaller. We speculate that this is due to the increased production use of IPv6. The use of MaxLength in IPv6 reflects much the same thing; in 2015, about half of ROAs had a MaxLength set to /36 or bigger, in 2019 the halfway point shifted toward /48.
And what about the use of MaxLength in ROAs? As we mentioned earlier, there is some discussion about the use of MaxLength. So we plotted the use of MaxLength over time in the graph below:
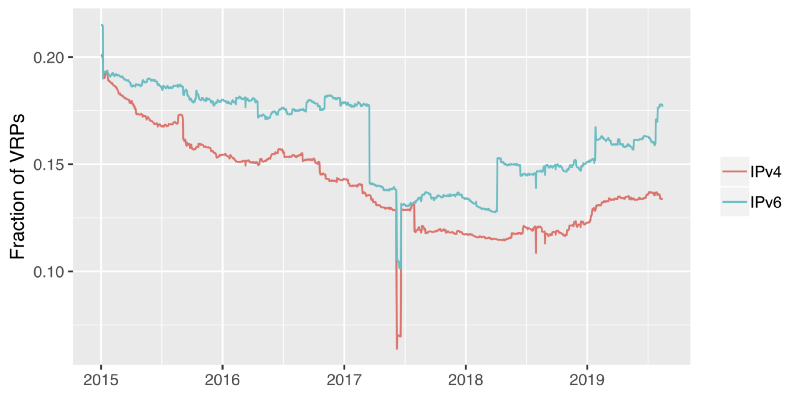
What the graph shows is the fraction of VRPs that have a MaxLength that is smaller than the prefix size. In other words: the fraction of VRPs that allow announcement of subprefixes smaller than the prefix covered by the VRP. The graph has two takeaways. First, the use of MaxLength is slightly more common for IPv6 than for IPv4 (not surprising given the larger address space, creating ROAs for every smaller subprefix would escalate very quickly for IPv6). Second, while the use of MaxLength was declining until early 2018, there appears to be a trend change from then, with the number of VRPs that uses MaxLength growing again from about March 2018. We speculate that this is a side-effect of operators actually starting to filter routes based on RPKI validation results. Consider: if you have a ROA for a /16, but you announce smaller subprefixes (e.g. multiple /22 prefixes), and you do not have ROAs for these smaller subprefixes, then any operator that performs RPKI-based filtering will reject the announcements for the smaller prefixes. And there are two ways in which you can fix this: you can create ROAs for all of the smaller prefixes, or you can set MaxLength correctly in the ROA for the /16. We speculate that the slight, but persistent rise in the use of MaxLength from 2018 onward can at least partly be explained by operators choosing the second solution to their announcements getting rejected by operators that filter based on RPKI.
To make the trend toward smaller prefix sizes even more visible, we end with two plots showing the average covered prefix size in VRPs and the average MaxLength in VRPs over time:
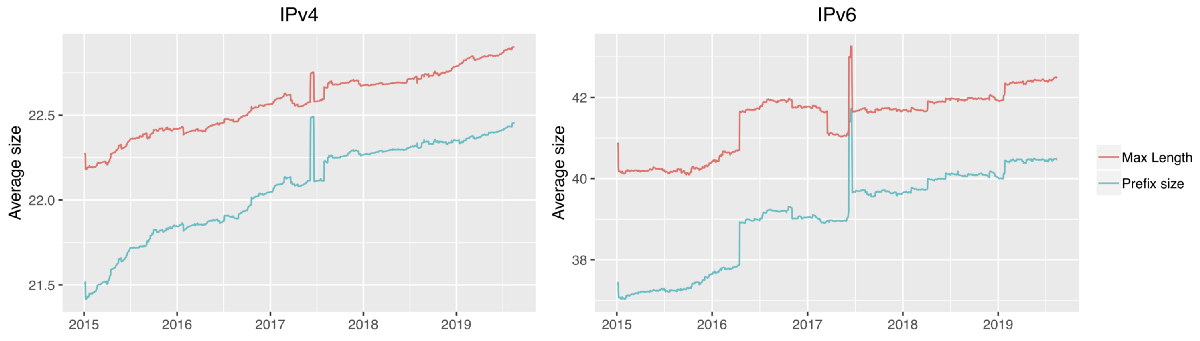
We leave the explanation of the spikes in 2017 as an exercise to the reader 😜 (hint: scroll back to the part about the growth of RPKI use at the top of the post).
A different look at growth: coverage and accuracy
That RPKI is growing is good news for the Internet. It significantly reduces the risk of route hijacks. What we have shown, however, is just that RPKI is growing, but not what that really means. To explain this better, we end this blog by looking at two things: coverage and accuracy.
To study these two aspects, we use a third open source tool from NLnet Labs: the Secure Routing Stats. This tool can take a set of VRPs that come out of Routinator, and combine this with statistics from the Number Resource Organisation about which prefixes have been assigned to which countries and up-to-date information about which prefixes have been announced in BGP from, e.g., RIPE RIS or another source such as Routeviews (which is the source we used). It can then output two things:
- Coverage: the fraction of announced prefixes in a country that are covered by a VRP.
- Accuracy: the fraction of announced prefixes in a country that are covered by a VRP and that are considered valid.
So, using a combination of Ziggy, Routinator and the Secure Routing Stats tool, together with the archived RPKI data from RIPE, NRO data and full table dumps from Routeviews roughly covering the past two years, we analysed coverage and accuracy.
Let’s start with coverage. The animation below shows the coverage per country over the period we analysed (click “play” to view the animation, date displayed at the top):
What the animation makes very clear is that coverage is growing, it’s growing rapidly, and growth is accelerating as we get closer to the present day. The fact that the whole map is showing increasingly darker colours means that coverage is going up all over the world. And that is good news; it means that an increasing number of Internet route announcements are protected by RPKI. What is also clear from the animation is that the growth rate differs by region. Latin America shows a high coverage from the get go, with a notable absence of Brasil, which is working hard on deploying RPKI in its National Internet Registry. Europe and the Asia Pacific region show increasing coverage over the entire period.
The lowest growth rate is observed in the ARIN region; we believe there are two reasons for this: the number of prefixes assigned to this region is historically very high (a left-over from the early days of the Internet), meaning that there is also a lot of ground to cover in terms of RPKI deployment. Second, the interface that ARIN provides for deploying ROAs is somewhat harder to use than those offered by, e.g., APNIC and RIPE, which may impact deployment (the tweet shown alludes to calling the ARIN RPKI UI “Magnificent Desolation”).
And we end with — what we believe to be — the most exciting animation: the one showing accuracy. This animation shows what fraction of announced prefixes are valid announcements, that is: they are covered by a ROA and validate correctly. We view accuracy as a measure of the quality of RPKI data; if the accuracy is high, it is safe to use RPKI data for filtering, as you are unlikely to filter legitimate announcements. Conversely, if accuracy were low, filtering would probably be unwise as you might drop legitimate, but poorly managed routes.
The animation below shows the development in accuracy for countries that have an accuracy of 90% or over. We specifically picked this cut-off, as accuracy is generally already quite high, and we wanted to show that it is still improving. So play the video below and see for yourself:
“what this data first and foremost shows is that RPKI is ready for the big screen”
We think the animation is pretty self-explanatory: the quality of RPKI data has grown from “already quite good” to “very high” over the past two years. And that brings us to our main conclusion: what this data first and foremost shows is that RPKI is ready for the big screen. The quality is now so good that there is really no reason not to protect your network from accepting route hijacks, so we urge operators to go ahead, and start filtering RPKI invalids!
Further reading
Running Ziggy on your own system
As we said earlier, we released Ziggy as an open source tool for researchers and other curious folks. Below, we explain how you can run Ziggy yourself to get the full set of verified prefixes for a date of your choice*.
*The archived RIPE data does not contain TA certificates for dates prior to March 10, 2015, so this is effectively the first date from which this will work. We have notified RIPE of this and are hoping it can be repaired.
Installing Routinator (and Rust) and Ziggy
The first thing you’ll need to do if you want to use Ziggy is to install Routinator. For detailed information on how to do this, we refer to the README in the Routinator repository, but we reproduce the simple approach below.
Step 1: install Rust
If you have not install the Rust programming language, you’ll need to install that first. Assuming you are on a UNIX-alike system (read: Linux, *BSD, macOS, …), the simplest way to install Rust is to run the following command from your shell prompt:
curl https://sh.rustup.rs -sSf | shFollow the instructions on your screen. The default settings are typically fine, as this will install Rust for your own user account only (also making it easy to clean stuff up if you decide you want to get rid of it). It’ll tell you when it’s done by saying: “Rust is installed now. Great!”. You’ll need to reload your shell profile, so log out and back in or re-execute the profile like so (example is for the Bash shell):
. ~/.bash_profileStep 2: build and install Routinator
Rust comes with its own package management in the form of so-called “crates” that you can install using the “cargo” tool. Using cargo, installing Routinator couldn’t be simpler. Simply execute the following command on your shell prompt and be a little patient while Routinator is compiled:
cargo install routinator
Step 3: initialise Routinator
Because Rust has added itself to your path, you will now immediately be able to run Routinator from the command line. Before Routinator can do its work, you’ll need to initialise it. Do this by invoking it from the command line as shown below:
routinator initIt’ll tell you you’ll have to agree to the ARIN Relying Party Agreement, which you can do by specifying the appropriate flag on the command line.
Step 4: get faketime (optional)
In order to be able to run Routinator on old date, we’ll need to be able to fake time. Fortunately, there is a good tool for that, called faketime. If it isn’t installed yet, you’ll need to install it using your package manager (e.g. yum, apt or brew).
Step 5: get Ziggy
Now that Routinator is installed, we can start with Ziggy. The first thing you’ll need to do is grab Ziggy from Github:
git clone https://github.com/NLnetLabs/ziggyStep 6: configuring and running Ziggy
Ziggy comes with a sample configuration file called sample-ziggy.conf, which you can actually use straightaway. So let’s go ahead and do that, and let’s run Ziggy for July 1st, 2019:
./ziggy.py -c ./sample-ziggy.conf -d 2019-07-01This should produce output that looks like this:
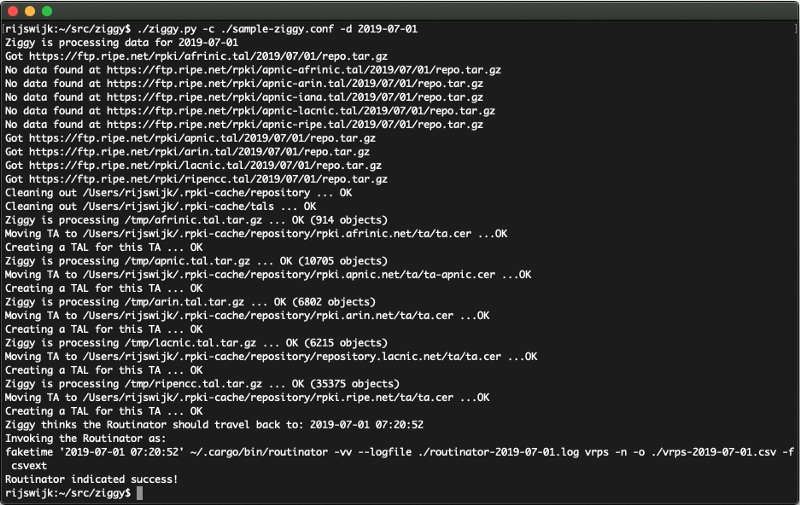
Now that’s quite a bit of output, so let’s go over what Ziggy has told you, starting from the top:
- First, Ziggy will tell you which date it its running for:
Ziggy is processing data for 2019-07-01 - Then, you’ll see it trying to fetch data from RIPE’s archives. It will try to fetch data for each of the five RIRs. Note that between October 2012 and April 2018, the APNIC repository had a somewhat different structure. Ziggy will automatically attempt to fetch both the ‘regular’ APNIC repository as well as the structure used between those dates, so you can safely ignore messages such as the one shown below; these simply indicate that that particular layout for the APNIC data did not exist on the specified date.
No data found at https://ftp.ripe.net/rpki/apnic-afrinic.tal/2019/07/01/repo.tar.gz - Once Ziggy has all the data it needs, it will clean out Routinator’s cache:
Cleaning out /Users/rijswijk/.rpki-cache/repository ... OK
Cleaning out /Users/rijswijk/.rpki-cache/tals ... OK - Then, it will unpack the data for each RIR repository and attempt to reconstruct the trust root (the “TAL” or “Trust Anchor Locator”). Routinator needs this in order to know what key to use to start verifying the objects in the RIR’s repository. The example below shows the output for the RIPE repository. First, Ziggy will show how many objects the repository contains:
Ziggy is processing /tmp/ripencc.tal.tar.gz ... OK (35375 objects)
Then, Ziggy will move the TA certificate (if it found one) to the correct location (note that this is inside the Routinator cache):
Moving TA to /Users/rijswijk/.rpki-cache/repository/rpki.ripe.net/ta/ta.cer ... OK
Finally, Ziggy will recreate the TAL for the repository:
Creating a TAL for this TA ... OK - Ziggy uses the timestamps in the RIR tarballs to work out the exact time of day when the dataset was collected. This time of day is then used when running Routinator. This is important because ROAs have a limited validity, and running Routinator with the wrong time of day may result in some objects not being accepted as valid yet, or as expired. For the example above, Ziggy told us the following:
Ziggy thinks the Routinator should travel back to: 2019-07-21 07:20:52 - Finally, Ziggy will invoke Routinator and shows you exactly which command it used to do so (so you can re-run this command later on, if you want to).
- The output will have been written to the directory from which you executed Ziggy into a file called vrps-2019-07-01.csv. If you used the default configuration, the output is the extended CSV output, which lists the URI for the validated object, the associated AS number, the IP prefix, the maximum length as set in the ROA and the validity (not before, not after) of the object.
And that’s it, have fun exploring the data!