Where Did My Packet Go? Measuring the Impact of RPKI ROV
Merely doing RPKI ROV does not provide any guarantees where your packet ends up. We conducted an experiment where we look into the impact of RPKI ROV on whether the packet ends up in the intended location based on active beaconing with two servers.

A guest post by Koen van Hove, contributed by Willem Toorop
This research is a collaboration between the University of Twente, RIPE NCC, and NLnet Labs.
For a long time, we have been encouraging operators to enable RPKI Route Origin Validation (ROV) in their networks. We still do, and again if you are not currently doing RPKI ROV, please consider doing so. However, what we have not yet fully explored is what effect ROV has on where your packet actually ends up. After all, the aim of the RPKI is to ensure that my packet ends up at its intended location, and merely doing ROV does not guarantee that.
Background
BGP and RPKI
Let us take a step back for a moment. The Internet, in its physical form, is essentially a large cluster of cables going all around the globe. Every source and destination must have an address, namely an IP address. These addresses are managed by the regional Internet registries (RIRs), such as RIPE NCC and APNIC. Figuring out which route to take requires something called the Border Gateway Protocol (BGP), which enables a network to announce to other networks which IP addresses can be reached via them. These networks are also called Autonomous Systems (AS), and they are assigned a unique number, an ASN. When another AS receives this announcement, they can propagate it further by prepending their ASN to the path. Repeat this several times, and one learns how to reach pretty much every IP address currently in use.
This is a system that largely hinges on “good faith” - there is nothing stopping me from announcing AS 1133(the University of Twente) as origin for 193.0.0.0/21 (the prefix used by the RIPE NCC). In the RPKI, I can make objects called Route Origin Authorisations (ROAs) that enable the rightful holder of the IP address prefix (in this case the RIPE NCC) to make verifiable statements about which ASN that prefix may originate from. In this case, the RIPE NCC has a ROA for 193.0.0.0/21-21 for AS 3333, the ASN assigned to the RIPE NCC. Additionally, the ROA states how specific the announcements may be (the maxLength attribute). For example, if an announcement for 193.0.1.0/24 for AS 3333 is also expected. The /21-21 here indicates that only the /21 announcement should be valid.
With the data that ROAs provide, an operator can classify incoming BGP announcements, and group them into three states: valid, invalid, and not found. As with everything BGP, what an operator does with these states is up to their policy, but generally speaking it is advised to reject invalids and accept valids and not founds. This best practice is called Route Origin Validation (ROV).
Route Origin Validation
There have been measurements into the adoption of RPKI ROV looking into who is doing ROV. Unfortunately, simply doing ROV does not mean that your traffic will not end up at an origin AS ROV marked as invalid. Even though you receive the full path via BGP, you do not specify the full path your packet should take when you send it onwards.
Let us take the previous RIPE NCC example. Imagine I announce 193.0.0.0/22 with AS 1133 as origin AS. As this is more specific than the announcement for 193.0.0.0/21 for AS 3333, generally speaking this announcement will be preferred. You receive two announcements: one for 193.0.0.0/22 with path AS 3320 → AS 1133 and one for 193.0.0.0/21 with path AS 3320 → AS 3333. You might do RPKI ROV, so you reject the first announcement and use the second one. However, your traffic still goes towards AS 3320(Deutsche Telekom), which does not do ROV yet. It receives your packet, sees both announcements from AS 1133 and AS 3333, and sends it to the most specific one. This means that even though you do ROV, your traffic still ends up in a different location than you intended. Fortunately, the inverse holds true as well. If you did not do ROV, so you accepted both announcements and used the most specific (which also went to AS 3320), and Deutsche Telekom did do ROV, then your traffic might actually end up at the intended location without you doing ROV explicitly.
As we can see, the impact of ROV is not as simple as just measuring how many ASes do ROV. We wanted to explore this further, and set up an experiment.
The experiment
We wanted to measure where the traffic goes. To do so, we have a ROA that authorises AS 211321 to announce 2a04:b905::/32-32 and 203.119.22.0/23-23. We announce 2a04:b905::/32 and 203.119.22.0/23 from Vultr (AS 20473) in Sydney, and 2a04:b905::/33 and 203.119.22.0/24 from ColoClue (AS 8283) in Amsterdam. If everyone would do ROV, then the traffic inside 2a04:b905::/33 and 203.119.22.0/23 (e.g. 2a04:b905::2) should go to Sydney.
Our hypothesis is that if one link in the chain is missing (i.e. one AS that accepts the more specific), then the traffic will not end up in the intended location. To measure this we have set up two RPKI publication points, parent.rov.koenvanhove.nl (2a04:b905:8000::1 and 203.119.23.1) and child.rov.koenvanhove.nl(2a04:b905::2 and 203.119.22.2). All traffic will go to Sydney for the parent (because that is the only place it's announced), and we measure where the traffic for the child ends up.
Every Internet measurement has bias. By using RPKI publication points, we can ensure a steady stream of Internet traffic that is more likely to do RPKI ROV (and drop invalids) than the average. After all, we assume that an organisation that runs an RPKI validator (and thus hits our publication points) is more likely to do ROV than an organisation that does not run an RPKI validator.
To check whether an organisation does ROV and drops invalids, we have set up a third publication point invalid.rov.koenvanhove.nl, which is accessible on 203.119.21.1 and 2001:ddb::1. The prefixes they belong to (203.119.21.0/24 and 2001:ddb::/48) have no less specific prefix announcements associated with them, and both have an AS0 ROA associated with them. This means that those networks that do ROV and drop invalids should never reach the invalid.rov.koenvanhove.nl publication point, as there is no route to it. This third publication point is also hosted at Vultr in Sydney.
Results
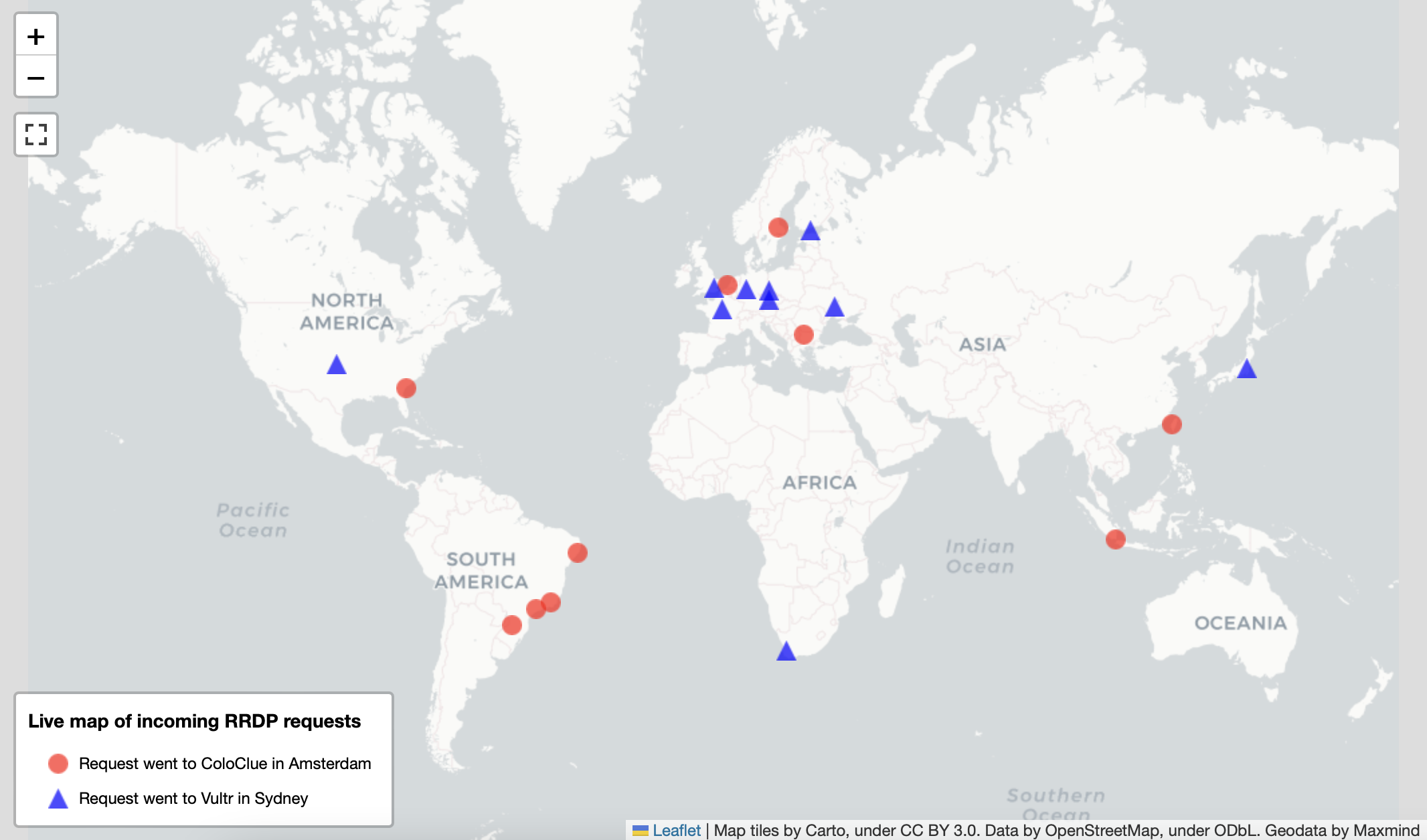
Roughly a quarter (25%) of traffic ends up at ColoClue in Amsterdam. The other 75% ends up at the intended location at Vultr in Sydney. The precise numbers differ slightly depending on whether you count the number of requests, IP addresses, IP prefixes (and which size), or ASes those IP prefixes belong to. However, checks with the NLNOG ring and RIPE Atlas show a similar image to this 75%/25% division. Interestingly enough, the physical location of the origin did not have a strong influence of where a packet ended up.
There are RPKI validators in Australia that had their traffic directed to ColoClue in Amsterdam and there are RPKI validators in Amsterdam that had their traffic directed to Vultr in Sydney.
There seems to be no clustering of either group at least geographically. On rov.koenvanhove.nl you can see an experimental live map of where traffic ends up:
Using the check with our always invalid, we end up with the following numbers:
| Ends up at ColoClue in Amsterdam | Ends up at Vultr in Sydney | |
|---|---|---|
| Drops invalids | 304 | 1650 |
| Does not drop invalids | 600 | 628 |
There is a caveat, namely that it seems like invalid.rov.koenvanhove.nl is not as well connected as invalid.rpki.cloudflare.com (e.g., while invalid.rpki.cloudflare.com is reachable from T-Mobile Thuis, invalid.rov.koenvanhove.nl is not), so the number of “drops invalids” is likely lower.
Challenges
Along the way, we stumbled upon some challenges. When we first started the experiment, over 99% of traffic went to ColoClue in Amsterdam. The only packets that did arrive were those from validators within Vultr in Sydney. Upon further investigation, it turns out that even traffic that reached Vultr would at their edge be rerouted to Amsterdam, as Vultr itself does not do RPKI ROV. We worked around this issue by also announcing 2a04:b905::/33 from Vultr in Sydney with a BGP community that would ensure that the announcement would not be propagated outside Vultr. It is however good to realise that without this workaround, all our traffic would have been misdirected.
Additionally, we noticed that not all networks that handle IPv6 traffic also support IPv6 on their validators. Initially the ROA for 2a04:b905::/32-32 was only hosted on parent.rov.koenvanhove.nl, which used to be IPv6-only. In our inspection at several looking glasses, we noticed that several networks, including large networks, would still consider the announcement from 2a04:b905::/32 unknown. We also got several reports from organisations where our IPv6-only ROA caused internal Validated ROA Payload (VRP) inconsistencies due to some validators supporting IPv6, and some validators not supporting IPv6.
Conclusion
We looked at what impact RPKI ROV has on where the packet actually ends up. We see that in a lot of cases the packet ends up in the intended location, even if the organisation itself does not do RPKI ROV, by merit of the upstream doing RPKI ROV. We also see that there are cases where the organisation does do RPKI ROV, but the upstream still sends the packet to the unintended destination. It highlights once again how important RPKI ROV is, but also how important it is to have a varied set of upstreams. In our initial case, Vultr acted as our only upstream, causing us to lose nearly all traffic.