Braving the Waves with Krill

If you have the luxury that your RIR, NIR or some other organisation offers an RPKI Publication Server that you can use, well then you're in luck. You would only need to set up a Krill CA instance – you can pretty much follow the guide we wrote for "Testing the Waters with Krill" to get you started.
However, if like us you need to run your own Publication Server infrastructure as well, or if you are just curious to find out how we did it, then read on! Note that there are a lot of similarities between this and our testbed setup, but rather than referring to the posts we wrote about our other instances we chose to repeat all the necessary steps here, so that this can be read as a stand-alone post.
Overview
We use two separate servers: one for our production CA, and one for our Publication Server and HTTPS (RRDP) and rsync servers for our RPKI repository.
We enabled multi-user support in our Krill CA so that the audit history for our CA will track which user made changes to our CA - e.g. this will tell us who added a specific ROA, and when they did so.
Publication Server Setup
We created a small virtual machine with 1 GB of memory, 1vCPu, 25 GB of local storage and a redundant block storage volume of 10GB which we will use for our RFC 8181 enabled Publication Server.
We run a single Krill instance for the Publication Server itself, and we use Krillsync to synchronise the RPKI repository content to dedicated directories. This content is served by NGINX in case of RRDP (https), and the ubuntu rsync package.
High Availability
By choosing to run our HTTPS proxy (NGINX) and rsync on the same host as our Krill Publication Server, we accept that these three applications share fate on a single host, and that our repository is temporarily unavailable in case this host is unavailable (e.g. if we upgrade the kernel and reboot it).
Practically speaking this is not an issue for us because we know that only our own CA publishes in our repository, and we know that we only need infrequent ROA changes. By default Krill re-issues the so-called RPKI Manifests and CRLs 8 hours before they would expire, so this means that even if our Repository would be unavailable - we would have 8 hours to deal with this.
As far as normal traffic and load goes for an RPKI repository of our size, we can see that running these components together can easily be done on a single small virtual machine (1 vCPU, 1GB of memory), as can be seen by the server load, memory usage and bandwidth in the graphs below:
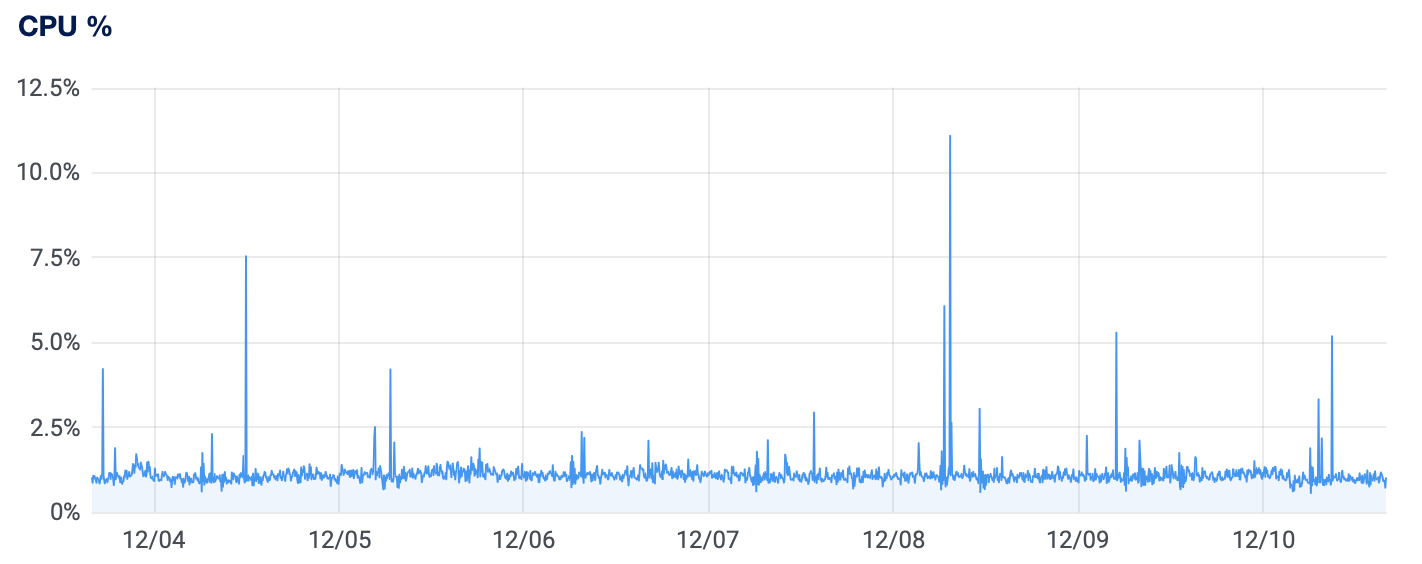
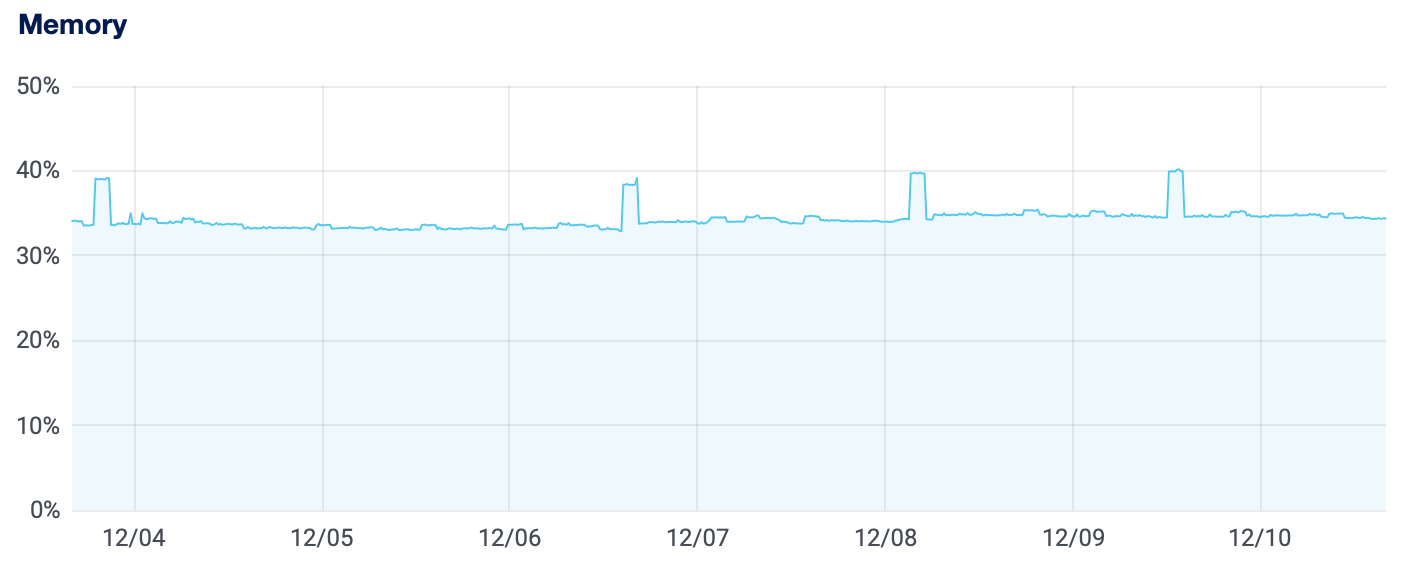
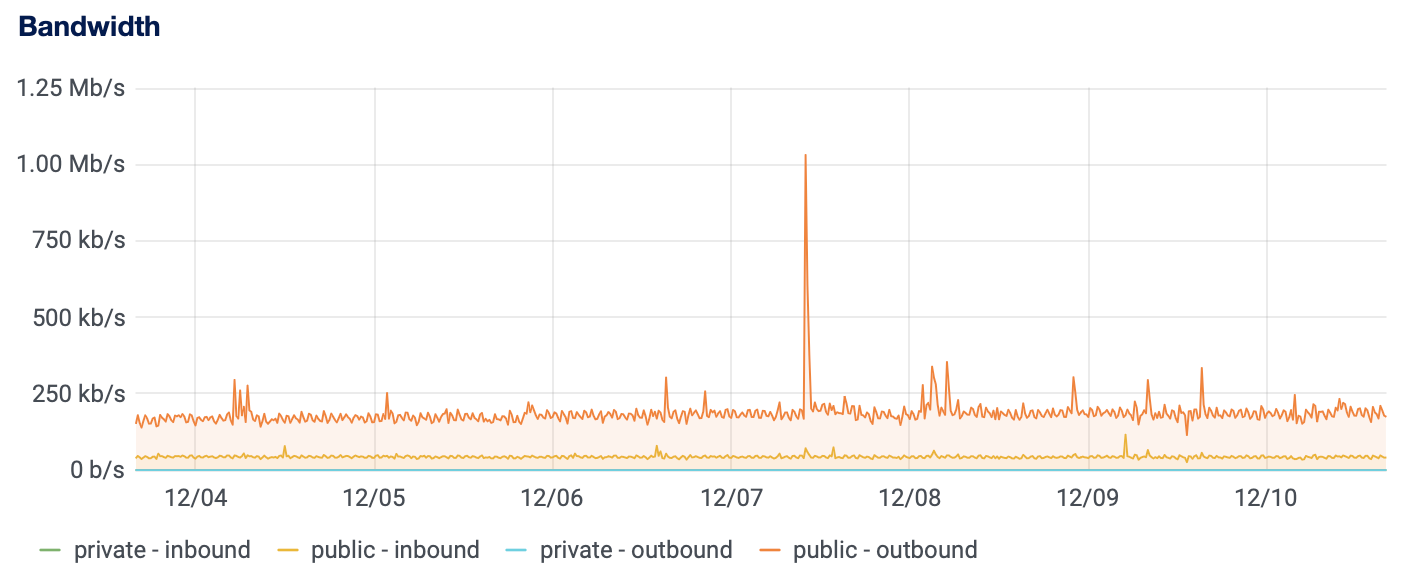
On the other hand, if you are running a publication server for a large repository where many CAs can publish, or if you just want to get to a higher level of availability then you may of course want to scale this up more. If you want read more about the tooling and ideas we have for this kind of set up, then please have a look at our thought on "Dishing up Krill" on a higher level.
Add NLnet Labs Package Sources
At NLnet Labs, we build krill packages for amd64/x86_64 architecture running a recent Debian or Ubuntu distribution, as well as Red Hat Enterprise Linux/CentOS 7 or 8. In order to make these packages available to our system we created the file /etc/apt/sources.list.d/nlnetlabs.list with the following content:
deb https://packages.nlnetlabs.nl/linux/ubuntu/ focal main
# Uncomment the following if you want to try out RELEASE CANDIDATES!
deb https://packages.nlnetlabs.nl/linux/ubuntu/ focal-proposed main
As you can see we added the sources for ‘main’, as well as ‘proposed’. Normally one would not use the latter, but in our case we specifically wanted to be able to install and test release candidates in this environment as part of our release process.
Then we added the NLnet Labs key and updated apt:
wget -qO- https://packages.nlnetlabs.nl/aptkey.asc | sudo apt-key add -
apt update
Install and Configure Publication Server
After adding the NLnet Labs package source we simply installed the latest Krill release candidate binary, from the proposed source which we included:
apt install krill
After installing Krill, and before running it, we replaced the generated config file at /etc/krill.conf. We stripped all comments and defaults that we are not using. Other than that we made sure that we are using a public URI for service_uri, and we disabled downloading BGP dumps in order to save memory. Have a look at a copy of our actual configuration file, well.. except for admin_token which we did not feel like sharing here:
###########################################################
# #
# DATA #
# #
###########################################################
# We use the default data_dir used by the debian package.
data_dir = "/var/lib/krill/data/"
###########################################################
# #
# LOGGING #
# #
###########################################################
# We will use syslog and the default log level (warn):
log_type = "syslog"
### log_level = "warn"
### syslog_facility = "daemon"
###########################################################
# #
# ACCESS #
# #
###########################################################
# Admin Token
#
# We use an admin token, rather than multi-user support. We
# will use the CLI as the primary way to manage this server,
# and we like to keep things simple.
admin_token = "not-sharing"
# Service URI
#
# We will use the public (base) URI for our (nginx) proxy, so
# that remote CAs can connect to our testbed.
service_uri = "https://prod-ps.krill.cloud/"
############################################################
# #
# OTHER SEVER SETTINGS #
# #
############################################################
# Disabble loading BGP Dumps from RIS for ROA vs BGP analysis.
# We don't need it on the Publication Server and not loading
# them will save us quite some memory.
#
bgp_risdumps_enabled = false
Remember that we decided to use a separate block storage for the data directory? Rather than changing the default data directory /var/lib/krill/data, we decided to use a symlink instead:
mkdir /mnt/volume_ams3_05/krill-data
chown krill. /mnt/volume_ams3_05/krill-data/
cd /var/lib/krill
ln -s /mnt/volume_ams3_05/krill-data ./data
IMPORTANT: There is one more thing that we need to do before we can start Krill. The default systemd unit file limits write access to the default data directory. Since we are using a different location we need to create the following override file. The easiest way to achieve this is by using systemctl edit krill and adding the following:
[Service]
ReadWritePaths=/mnt/volume_ams3_05/krill-data/
Now that this has been done we can enable and start Krill, and review the syslog messages to see that all is good:
systemctl enable --now krill
journalctl -u krill
Test the Krill CLI
In order to use the Krill CLI krillc more easily we added the auto-generated value of the admin_token directive in our krill configuration file to our our profile:
export KRILL_CLI_TOKEN=”do-not-overshare”
We can then see that krill has started, and we can connect to it from the local machine using krillc info
Version: 0.9.3-rc3
Started: 2021-11-30T09:07:07+00:00
Initialise the Publication Server
After checking that Krill was running properly we initialised our Publication Server with its public URIs using the following command:
krillc pubserver server init \
--rrdp https://rrdp.krill.cloud/ \
--rsync rsync://rsync.krill.cloud/repo/And then we verified that an intitial, empty, RRDP notification file had been created at /var/lib/krill/data/repo/rrdp/notification.xml:
<notification xmlns="http://www.ripe.net/rpki/rrdp" version="1" session_id="1acc31b0-290a-49bd-a5ab-53a009343886" serial="0">
<snapshot uri="https://rrdp.krill.cloud/1acc31b0-290a-49bd-a5ab-53a009343886/0/c226273292d3267a/snapshot.xml" hash="cd39e71f035dc0457f858f0d61ef34d276148cd3f630dee10a40f18215ce11d6" />
</notification>Install and Configure krill-sync
Krill-sync is a tool that we developed at NLnet Labs specifically to help scaling up the RPKI Repository to potentially multiple RRDP (https) and rsync servers.
In this current setup we run Krill, NGINX and rsync on a single node, but we still like to use Krillsync to manage the content that we serve, as this will allow us to restart Krill without impacting our repository, and it will allow us to leverage the improved support for rysnc directories in Krillsync.
We installed Krillsync and set it up to use a directory on the redundant volume. There is more than one way to do this, but we chose to use symlinks to map default its directories to their target:
apt install krill-sync
cd /var/lib/krill-sync
mkdir -p /mnt/volume_ams3_05/repository/rrdp
chown krillsync. /mnt/volume_ams3_05/repository/rrdp
ln -s /mnt/volume_ams3_05/repository/rrdp
mkdir -p /mnt/volume_ams3_05/repository/rsync
chown krillsync. /mnt/volume_ams3_05/repository/rsync
ln -s /mnt/volume_ams3_05/repository/rsync
Because we run krill-sync on the same machine as our Publication Server, we opted to map --source_uri_base to the location on disk where Krill saves the RRDP files it generates - rather than going through its web server:
krill-sync https://rrdp.krill.cloud/notification.xml \
--source_uri_base /var/lib/krill/data/repo/rrdp/
After checking that this worked properly we set up the krillsync user crontab to run it every minute. Synchronisation is cheap to run and will not update anything if there are no changes at the source.
Install NGINX and Let's Encrypt
Krill's embedded web server is not intended for public access. So, we decided that we will NGINX for safe and efficient access to our Krill instance UI and API, as well as our RRDP repository data and Trust Anchor resources.
First we installed nginx:
apt install nginx
Then we removed /etc/nginx/sites-enabled/default and then added two configuration files of our own.
First we added /etc/nginx/sites-enabled/prod-ps.krill.cloud so that we could proxy requests from publishing CAs to the Publication Server krill backend:
server {
server_name prod-ps.krill.cloud;
client_max_body_size 100M;
# Pass requests to the krill backend.
location / {
proxy_pass https://localhost:3000/;
}
listen 80;
}Then we added /etc/nginx/sites-enabled/rrdp.krill.cloud to serve the static RRDP files managed by krill-sync :
server {
server_name rrdp.krill.cloud;
# Maps to the directory where krill-sync stores RRDP files.
location / {
root /var/lib/krill-sync/rrdp/;
}
listen 80;
}We did not configure anything for HTTPS yet, because - conveniently - Certbot will offer to do this for us:
systemctl restart nginx
apt install certbot
apt install python3-certbot-nginx
certbot --nginx
Then we added the following to the crontab of root:
# Automate Let's Encrypt certificate renewals
0 12 * * * /usr/bin/certbot renew --quiet
Configure rsyncd
After we did the set up for Krillsync we configured and enabled rysnc to serve the RPKI repository content. We created /etc/ryncd.conf as follows:
uid = nobody
gid = nogroup
max connections = 50 # prevent that the server can be easily DoS'ed
[repo]
path = /var/lib/krill-sync/rsync/current/
comment = RPKI repository
read only = yesAnd then enabled the rsync service:
systemctl enable --now rsyncProduction CA Server with Multi User Access Setup
Now that we set up the Publication Server we focused on setting up a production CA environment.
First we added the NLnet Labs package sources and installed the krill binary as described above in the section for the Publication Server setup. But, before enabling krill as a service we modified the configuration file /etc/krill.conf. We stripped all the defaults that we were not using in this setup.
The start of our configuration file looks like this:
###########################################################
# #
# DATA #
# #
###########################################################
# We use the default data_dir used by the debian package.
data_dir = "/var/lib/krill/data/"
###########################################################
# #
# LOGGING #
# #
###########################################################
# We will use syslog and the default log level (warn):
log_type = "syslog"
### log_level = "warn"
### syslog_facility = "daemon"
###########################################################
# #
# ACCESS #
# #
###########################################################
# We use an admin token for the CLI
admin_token = "not-sharing"As mentioned, we wanted to enable access to our Krill CA UI for named logged in users, rather than sharing the admin_token between colleagues. In our previous installation we used OpenID Connect with Azure Active Directory for this purpose. This time around we opted for using the simpler approach of defining users in our Krill configuration file:
# We enable multi-user acces to the web UI, using user names
# and passwords specified in the [auth_users] section below.
auth_type = "config-file"
[auth_users]
# Notes:
# - users MUST have a role to login, all our users get 'admin'
# - use `krillc config user` to get values for the hash and salt.
# - make sure to add attributes={ role="admin" } when you add users
"tim@nlnetlabs.nl" = { attributes={ role="admin" }, password_hash="..", salt=".." }Furthermore, in the same way as we had done for our Publication Server, we then set up a symlink to map /var/lib/krill/data/ to the redundant block storage volume, and used systemctl edit krill to allow read/write access by our krill process.
Then we set up an NGINX proxy and Let's Encrypt (using Certbot) to ensure that we can log in to our CA remotely. So we installed the nginx binary just like described earlier, removed the default site configuration and just added the following proxy configuration under /etc/nginx/sites-enabled/prod-ca.krill.cloud:
server {
server_name prod-ca.krill.cloud;
client_max_body_size 100M;
# Pass requests to the krill backend.
location / {
proxy_pass https://localhost:3000/;
}
listen 80;
}
Then we set up Let's Encrypt and automated certificate renewal using Certbot, just like described earlier for the Publication Server set up.
Monitoring
For monitoring our setup we chose to use the alerting support from our cloud provider to keep an eye on CPU, memory and disk usage.
To make sure that our Krill instances are healthy and can be reached, we decided to use an external monitoring bot to query the /metrics end-points on both machines. Krill exposes a lot of information here that can be used by prometheus and Grafana, but for the moment we just want assurance that everything runs.
In future we would like to look into using a separate routinator setup to monitor that the ROAs we configured in Krill are also seen to be available and valid in the global RPKI. But this will have to wait a bit for now.
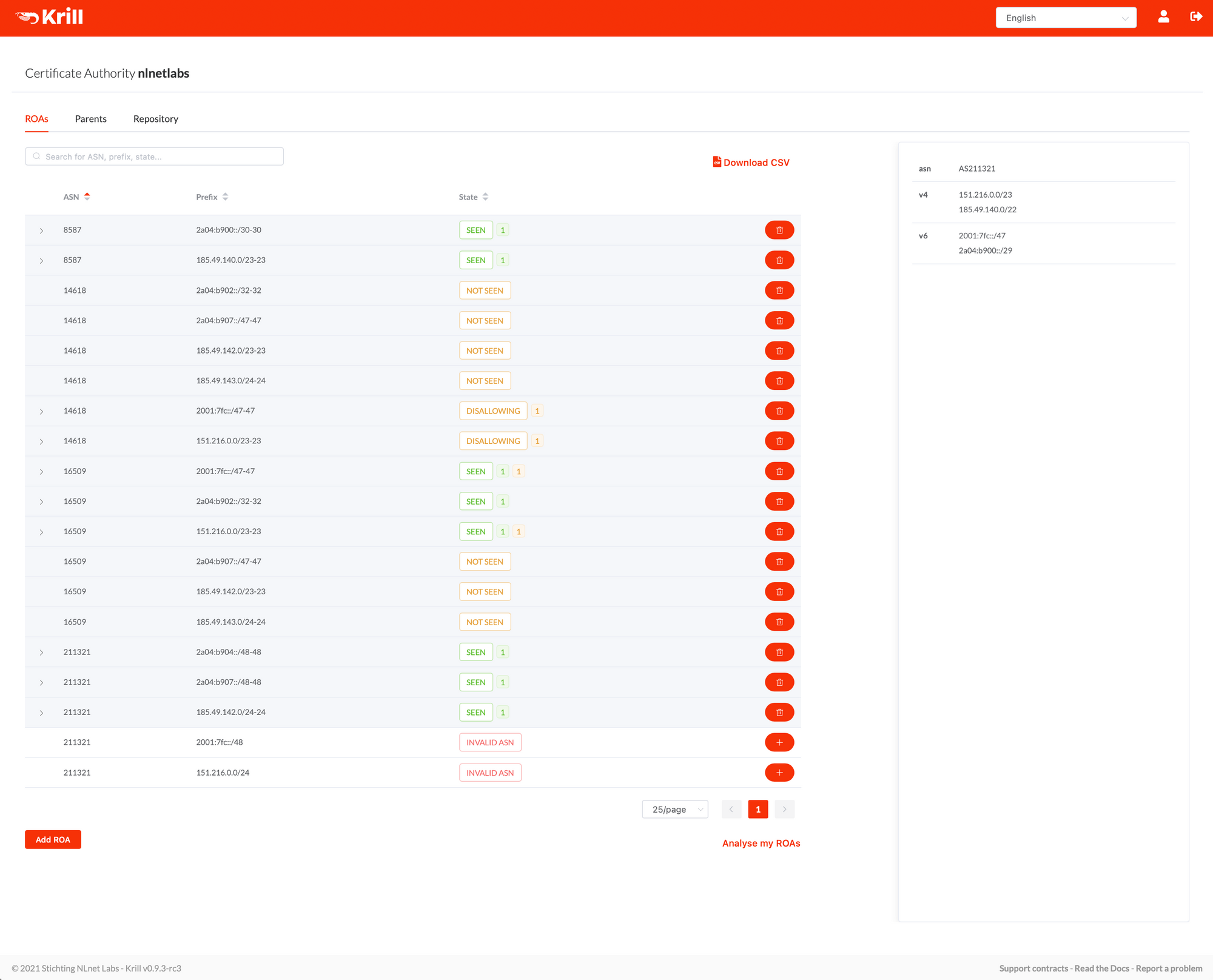
Production CA Instance
Now that we had our servers installed, configured and running, we could start setting up our Certification Authority instance 'nlnetlabs', using our Publication Server, and use RIPE NCC as our parent CA organisation.. the process for this from the CA's side no different than described in our documentation under "Getting Started with Krill".
In addition to this we just needed to add the nlnetlabs publisher to our Publication Server. You can read more about using krillc to manage publisher here, but for your convience let's quickly show what needed to be done.
After downloading the 'Publisher Request' XML from our CA, we copied it to our Publication Server and saved it as pub-req.xml and ran the following command:
krillc pubserver publishers add --request ./pub-req.xmlThen we copied the 'Repository Response' XML shown on the command line and uploaded it in our CA UI. Now that our CA knew where it could publish it automatically requested a certificate from its parent (RIPE NCC) - which was received a couple of seconds later. All that remained was to set up our ROAs – including some ROAs for RPKI invalid beacons for research - and called it a day...